I am sure that you are familiar at some level (perhaps very familiar) with distributed computing and some of the applications that it has been utilized in recently. The most recent popular efforts have been the SETI distributed project, and before that, the distributed.net effort to crack encryption keys. Other examples of distributed computing efforts have involved text searches and comparisons much like what the NSA historically has done, and sequence searches and comparisons of DNA to localize genes that are currently underway at companies like Celera. Indeed. a new effort by IBM will involve distributed computing techniques to allow molecular biologists and biochemists to perform conformational searches of protein structure to elucidate the rules which govern protein folding.
There are a couple of different ways to approach distributed computing or cluster-based computing. One distributed computing perspective is where there are not many interdependencies within the dataset. This method is useful in situations where many computers are connected to a wide ranging network, typically the Internet, or an intranet, where each computer can be doled out a specific portion of a problem, the answer to which is not dependant upon any of the other portions. This works very well for problems that can be cut up into completely independent pieces such as in distributed.net projects, where the task is to break an encrypted message by trying one key at a time. In this case, testing any one key does not depend on the result of any other key to obtain a solution. Digital film companies can also use this approach for making moves with 3D rendering farms. In this case, calculating each pixel can often be computed independently of any other pixel unless you are doing raytracing etc where you would have to use another method such as parallel computing.
Parallel computing is a method whereby each CPU gets information from other CPU’s before proceeding to the next step. This approach is typically used for large problems with significant interdependencies like protein folding. Other examples include combustion research, modeling nuclear reactions, classification of images, looking for genes, performing structural calculations in architecture, weather calculations, or analysis of drug activity to search for better drugs etc… The potential uses are myriad.
All of this said, running data on supercomputers or dedicated parallel clusters is expensive from a hardware perspective and from a humanware perspective. Indeed, the demands are such that even getting time on your local supercomputer can be a hassle. When you do get a block of time, you have to generate a chunk of data, send that data to the personnel running the supercomputer, wait for that data to get queued and then processed, and then either go and get the results or wait for someone to send them to you. One would think that with all of this hassle, there must be a better solution. Now imagine, what if you were able to analyze your data, or perform analysis using drag and drop using locally available desktop computers that are also used for other productivity purposes? It should also be noted that this is nothing really new. Back in 1989 when OS X was arguably NeXTstep, there was an application called Zilla.app that was perhaps one of the coolest and most innovative bits of code ever written. Zilla.app was written by Richard Crandall and the application was used for some time at NeXT to perform cryptography and do video compression. This application was available on all NeXT computers and provided a graphical user interface to select computers on an available network to create what was called a virtual supercomputer or a “community supercomputer” which would then automatically distribute calculations to the various available CPU’s to be run simultaneously or even at different times. In fact, on NeXT computers configured for education environments, Mathematica came packaged with the computer and I seem to remember some documentation perhaps in the NeXT On Campus literature concerning the application of Mathematica and Zilla.app.
More recently, there are a number of companies that are looking to take advantage of this concept commercially, like Dauger Research and Wolfram Research and there are even academic groups and schools using parallel computing for the Macintosh pioneered at UCLA with a project that is using Macs in a cluster based environment. However, while impressive, these efforts require significant expertise on the development of parallel code and math for specific applications.
This illustrates some of the problems associated with the integration of distributed and parallel computing for the vast number of scientists and engineers (and artists) who have no computational science backgrounds and do not know how to program, but could dramatically benefit from distributed computing. Now, imagine not knowing how to program a single line of code and being able to enable distributed computing across anywhere from a couple to several hundred individual machines with a modicum of clicks. Or being able to start running a calculation across those machines by using drag and drop. Where I am going with this is a desire for Apple to integrate this functionality into OS X and provide a means by which software companies like Adobe, Research Systems and others can make calls to distributed functionality and integrate distributed computing abilities into their software for specific functions that could benefit. By doing just this, Apple could again revolutionize the computing industry by providing the opportunity for the next real killer app. or killer feature and drive sales of the Mac much like Visicalc did for the Apple II. Imagine the possibilities when companies that take advantage of the built in distributed computing inherent in OS X.
Companies that perform high end Photoshop work, or video production for film production houses that currently have to spend incredible amounts of money on SGI rendering farms that also require significant outlays of cash for UNIX and parallel computing savvy support staff could make digital movies cheaper lowering the bar for the independents. Apple could even use this feature to drive sales of their own professional video production software, and again, machines. But since this is a column about the use of Macs in the sciences, I should point out that great advances could also be made possible by giving true supercomputer access to scientists and engineers who currently find it difficult to obtain time on overtaxed supercomputer resources. Not every scientist has the resources available or the skills to program efficient parallel code, but again, what if programs that scientists use on a daily basis had easy access to distributed computing calls with a couple of buttons? GridMathematica is doing something like this, but the functionality is entirely within the Mathematica environment and it is not as easy to enable as it could be. Additionally, you still have to know something about parallel code and the math behind many of these calculations.
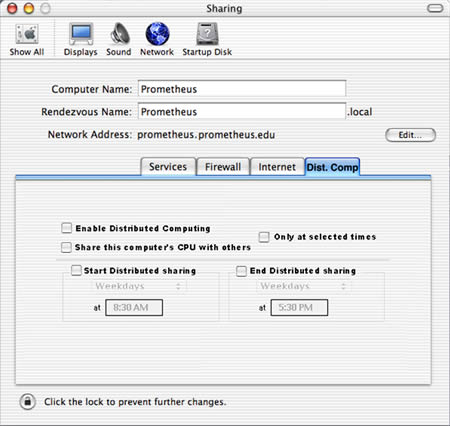
What I envision is a simple setup with control panels like the one below. Within this paradigm, like that of Zilla.app, computers will automatically
configure themselves to provide CPU cycles at specified times if network computing is enabled. If task ends, or the time period at which a computer is available ends, the computer will hand off data and revert to normal CPU allocation.
Granted, this approach will never supplant the really high end stuff from Cray, SGI, IBM, Hitachi and others, but it will enable significant advances to be made for a lot less money and potentially faster than could be done by waiting for time on a limited number of supercomputers.
Is this a viable alternative from a business perspective and what about connectivity and cooling requirements for supercomputers? Most of the physical cost of parallel supercomputers like the Cray X1 is in the data pipelines for data transfer back and forth. And don’t forget the cooling requirements and the costs associated there. For instance, in order to cool these systems it is not uncommon to have an entire floor beneath the supercomputers configured for refrigeration in an attempt to cool the rooms the supercomputers are located in and other solutions can seem truly bizarre to the person familiar with the typical personal computer in that some supercomputers are liquid cooled by immersing, flowing or spraying non-conductive cooled liquid (Fluorinert) directly onto the CPU and memory components. Let me tell you, it is an interesting experience looking through little windows in the sides of these systems and seeing liquid bubbling and flowing around. Strange, but this is a reality with some massively parallel systems.
As far as data interconnectivity goes, there are also some applications in supercomputers that would be unfamiliar to desktop computer users. However, 100 baseT or Gigabit ethernet is adequate for many problems, and I will bet that Apple could significantly expand its market for those that do not want/need or cannot afford the Crays and their ilk. Along networking lines, we should also mention that Apple has recently made an announcement that could enable easy and inexpensive solutions for massive amounts of data to be transferred back and forth in parallel computing paradigms. This announcement of IP over Firewire support is much like the Firenet from Unibrain and will allow full use of TCP/IP protocols over Firewire allowing Macs to use existing IP, AFP, http, FTP or whatever TCP/IP methods exist over a protocol with much greater bandwidth. Additionally, Rendezvous is completely supported in Apple’s solution for configuration, name resolution and discovery making many of the pieces available for parallel and distributed computing to be supported in OS X.
Because all Apple computers shipping for the last few years have had Firewire ports standard, there already exists a built in infrastructure for distributed or parallel computing nodes in many companies, organizations, schools, universities and labs at speeds much greater than the 10/100 Ethernet speeds previously possible. Now, it is true that gigabit Ethernet is a bit faster than current protocols for Firewire, but most of the installed base of Macs in the last few years does not have gigabit Ethernet and we should note that the Macs to be sold in the future should have new Firewire standards built in such as 1394b with much higher bandwidth capability in the neighborhood of 800-1600 Mbits making a dramatic jump in performance possible among other conveniences such as longer distances being supported. This solution also gets around potential security issues with distributing data as the data could be distributed on completely independent local networks to machines that also happen to be connected to the Internet. Of course there are other problems to address such as how well OS X scales in terms of CPU number and the amount of memory it can address in current 32 bit architectures, but presumably, some of the issues are being examined if OS X is ever to move to a 64 bit architecture.
So, where does this leave us? Today, for less than $20,000, about two thirds what a single SGI Octane will run you (from personal experience) one could get 8 dual Ghz G4’s with more RAM and hard drive space than you could get with that SGI, and potentially much greater performance for anything from rendering 3D movies to combustion and plasma research to sequencing etc… This could be a real coup allowing for Apple to also better position themselves in the business markets, get larger contracts from companies that perform large scale engineering or construction, bioscience or pharmaceutical companies and certainly universities bringing the original application for distributed computing, Zilla.app full circle from the NeXT computer to OS X.